 LiU startsida
LiU startsida
Image Processing Operations Developed in WITAS
In this section we breifly describe image processing based operations which have been developed within the project for the purpose of providing control data to the autonomous flying vehicle. Some of them have been implemented in the IPM of the helicopter, while other have been tested on simulated image data, but cannot be implemented in the limited computational environment currently used for the IPM.While not developed within the WITAS project, two methodologies of great importance have been the representation of information using channel representation [gg2000g] and a learning structure using the channel representation [gfj03]. These methodologies have been used in several of the subprojects and allowed development of uniquely powerful operations.
Channel Smoothing of Colour Images
We have developed techniques for decomposition of RGB component colour images into a set of channel images. This and a corresponding synthesis to a colour image allows image operations to be performed in the decomposed channel space. In the report [fgw02], we demonstrate that averaging on the channel images constitutes an edge preserving filtering method, and we also demonstrate how boundaries can be detected as a change in the confidence of colour state.
Robust Multi-Scale Extraction of Blob Features
The channel decomposition technique has been extended to a method for detection of homogeneous regions in grey-scale images, representing them as blobs. In order to be fast, and not to favour one scale over others, the developed method uses a scale pyramid. In contrast to most multi-scale methods this one is non-linear, since it employs robust estimation rather than averaging to move through scale-space. This has the advantage that adjacent and partially overlapping clusters only affect each other's shape, not each other's values. It even allows blobs within blobs, to provide a pyramid blob structure of the image.See the paper [fg03] for more details.


Blob feature extraction example. Left: input image. Right:
a rendering of the estimated blobs on a green background.
Sucessive Recognition using Local State Models
Using the channel representation we have developed principles for how a world model for successive recognition can be learned using associative learning. The learned world model consists of a linear mapping that successively updates a high-dimensional system state using performed actions and observed percepts. The actions of the system are learned by rewarding actions that are good at resolving state ambiguities. As a demonstration, the system is used to resolve the localisation problem in a labyrinth in the paper [pf02].The system is also described in a slightly different context in the report [forssen01c].
Window Matching using Sparse Templates
Real-time updates of position and heading on hardware with limited capacity requires fast region tracking techniques. In the report [forssen01b] we describe a novel window matching technique. We perform window matching by transforming image data into sparse features, and apply a computationally efficient matching technique in the sparse feature space. The gain in execution time for the matching is roughly 10 times compared to full window matching techniques such as SSD, but the total execution time for the matching also involves an edge filtering step. Since the edge responses may be used for matching of several regions, the proposed matching technique is increasingly advantageous when the number of regions to keep track of increases, and when the size of the search window increases. The technique is used on the WITAS airborne platform in the camera position and heading update method described below.
Updating Camera Location and Heading using a Sparse Displacement Field
For situations when GPS and INS information is uncertain, and as a backup should these systems fail, we have developed a system for updating an initial position and heading state description using image frame to frame correspondence only.In each frame a sparse set of image displacement estimates is calculated, and from these the perspective in the current image can be found. Using the calculated perspective and knowledge of the camera parameters, new values of camera position and heading can be obtained.
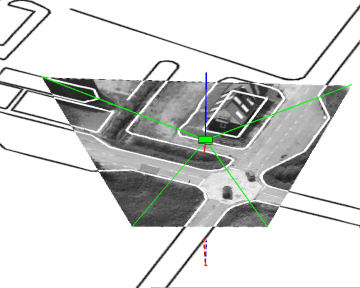
Position estimation using a homographic model. The estimated camera position is marked as a green box. (click to view movie).
The resultant camera position and heading can exhibit a slow drift if the original alignment was not perfect, and thus a corrective alignment with GIS-data should be performed once every minute or so.
See the position and heading update method is described further in [forssen00].
Two-Dimensional Channel Representation for Estimation of Multiple Velocities
Using a two dimensional channel representation with small but overlapping Gaussian kernels we have developed a motion estimation technique that can accurately extract multiple velocities near motion discontinuities. This is accomplished by encoding individual optical flow constraints, and averaging them in the channel representation. A localised decoding scheme accurately extracts multiple solutions together with an estimate of the covariances. We employ the method in optical flow computations to determine multiple velocities occurring at motion discontinuities.See the paper [sf03] for more details.
Unrestricted Recognition of 3-D Objects for Robotics Using Multi-Level Triplet Invariants
A method for unrestricted recognition of 3-D objects has been developed. By unrestricted, we imply that the recognition shall be done independently of object position, scale, orientation and pose, against a structured background. It shall not assume any preceding segmentation and allow a reasonable degree of occlusion. The method uses a hierarchy of triplet feature invariants, which are at each level defined by a learning procedure. In the feed-back learning procedure, percepts are mapped upon system states corresponding to manipulation parameters of the object. The method uses a learning architecture employing channel information representation. The work also contains a discussion of how objects can be represented. A structure is proposed to deal with object and contextual properties in a transparent manner. See [gm02].
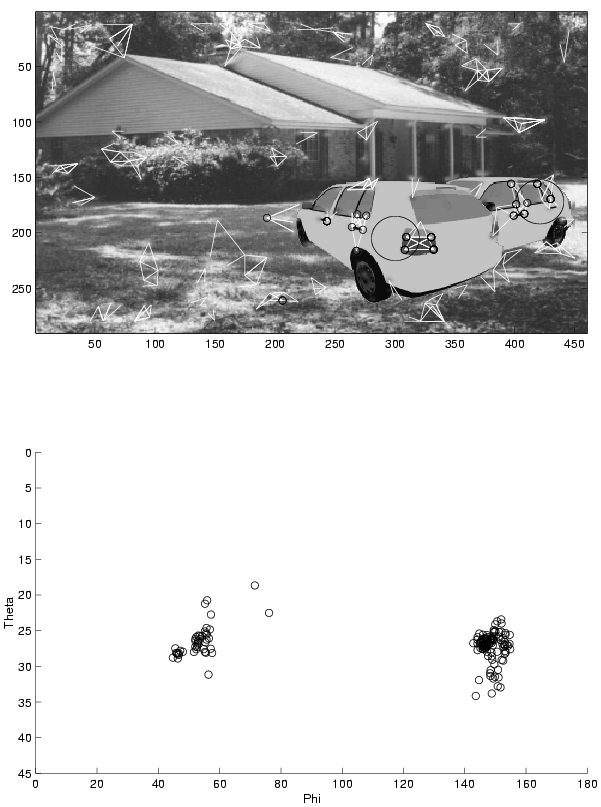
Test of recognition of pose for two partially occluded objects
against a structured background. The lines are the first level
triplets, the small circles indicates the accepted triplets and the
large circle is the estimated position of the object. The circles in
the plot are the pose estimates from the triplets. Theta is the angle
between the camera axis and the horizontal plane and phi is the
rotation in the horizontal plane (phi=0: the car is seen from the
front).
Scale and Orientation Invariant Recognition of 2-D Blobs for Aerial Navigation
The method uses a description of local regions in the form of blobs, which can be stored as a compact reference for comparison in navigation. The representation is normalized with respect to scale, orientation and perspective transformations. The method uses a learning architecture employing channel information representation.Last updated: 2012-06-01
